Managing Cloud Services and The Surprising Role of Jails...

%20Saif%20LinkedIn.jpeg)
Saif Al-Zobaydee
Systemutvecklare
The Deployment Problem
“Deploying” an application is fundamentally done by copying your program files to a publicly exposed, physical computer, aka thy server. Deploying like this means storing your application with all its needed dependencies (pre-)installed on that server.
Copying files between different servers could sometimes lead to missing some needed files, forgetting to create that setting in the new environment, or creating a configuration drift in many other scenarios. You could nail down all the required steps to set up your application and still be getting an error, and who have not heard “it works on my machine” before? :)
There are many different schools on how to do things best and…
I'm not here to convince you what the right path is, but serverless solutions are like magic wands for engineers, except you don't need to say any spells, and they actually work. With auto-scaling lambda/functions, SNS, queues, and managed DBs should be (when qualified) any solutions architect's first choice. They could empower and alleviate much of the management burden from engineers and create time to focus on building new solutions that deliver business value faster instead of managing current (or, even worse, old?) systems to make them work. Also, if you are stuck with an outlandish monolith of an application, then you already know it’s past due time to chop some branches and start splitting where it makes sense (but there are toolings for monoliths that I’ll get back to which should make things a lot easier, it’s a modern age we live in after all).
but one thing is used everywhere in the cloud, which is containers; they are the backbone of the Cloud. I’m only here to get the base in place to build upon bigger solutions; I also wish for us, that’s you and me, to always understand things beyond the buzzwords.

It Started in Jails…?
So what is a Linux container? A container is always described as a running instance of an image. Sure, but what is it technically? A container is an isolated groups of processes. This cool tech that we today call container started around the year 2000 in jails… well, a FreeBSD jail at least, explaining the isolation of processes, network access, and other known and used container concepts :)
The Puzzle Pieces/Concepts of Containers

There are four puzzle pieces to containers that everyone needs to have in place, and these are:
1. The Linux process:
A process is an active program (executable file) running on your machine. Does your container run a web app? That’s a process. Does it run a DB? It’s a process. Each process has, for instance, its own virtual memory address space; processes are created and destroyed all the time. The usage is unlimited, and you can list what processes are running on your machine by typing ps
~ ps ✔
PID TTY TIME CMD
55719 ttys000 0:00.06 /Users/abc/Applications/abc.app/Content
55721 ttys000 0:34.40 -zsh
55907 ttys000 0:00.37 -zshNote that a PID = process ID is where everything that process does get linked/tracked (easiest by its PID) back to the process itself.
2. The Linux Namespaces:
This is a Linux kernel feature that partitions the resources; it is here where the container can control what an application can see, like a directory tree, process Ids, and IP addresses, among others. So imagine you have a containerized app sending a request (starting a process) to an API searching for the word ‘serverless’ and another containerized app searching for ‘it’s a physical server’; both apps are sending similar requests. They can query the same site; how does your machine figure out what response should go to which container? Well, namespaces would track each process, isolate them, and then return the response to the correct process requesting it. Cool, right?
3. cgroups (Control groups):
cgroups is where the Linux kernel control/limit the resource usage of the container. groups use systemd to better control the isolated processes instantiated by containers. There is some interesting math for CPUShares and memory, but it is outside the scope of this article. Just think, cgroups groups your process into hierarchical sets where usage of resources can be monitored and limited.
And finally, 4. Union file system:
Called a file system, but is it? UnionFS mounts itself on top of other filesystems. It can be layered on top of different directories and CD-ROMs, and it even merges separate software package directories and overlay them to create a single unified filesystem interface.
containers use UnionFS to efficiently encapsulate and streamline applications and their dependencies into a set of minimal, clean layers.
Using containers
To use a container, you would pull down an image (a static executable file that is read-only to run as the base of your container, it could be ubuntu, MySQL, Apache, or whatever you want to run your application on) from a registry, but we can also create our own images.
Image naming syntax:
When pulling from an image registry, you would search for images; you can also find them with this syntax:
registry_name/user_name/image_name:tag
where “tag” would denote the version of the image.
Visualization:
Here is an example of a Dockerfile to create a container
#getting red hat enterprise Linux
FROM registry.access.redhat.com/rhel
COPY ./app
RUN make /app
ENV LogLevel "info"
CMD python app/app.pyThis will pull the red hat and run our app on it.
also, when not choosing a tag, it will default to the latest version
Worth noting that the code above is what makes the container run our application (in an isolated process), so for our Dockerfile, we are telling it to run python
If we had a MySQL server, we would tell it to start the MySQL service, and if we were running our application in an apache server, the last thing we would command is to run the apache processes. This behavior/command can be overwritten on runtime if it’s needed.
ProTip for Image layering/layered architecture:
This is interesting; although it might not look like it, every RUN command we add to our Dockerfile will be on its own layer
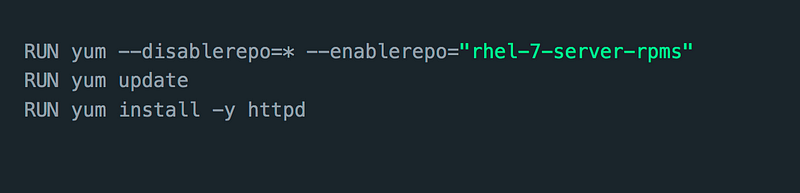
This will create 3 layers in our container. Having many layers will increase the size of the image, and we do want to keep our image size to a minimum; thankfully, we can come around to that by using the && like here:

Of course, you would even want to break it down even more, and it’s even best practice to have a Multi-stage builds, meaning you can have a “build application” set up which contain all the needed dependency, which usually create a bigger image size but it also separate and reduce the “release application” container, creating tiny images :)
https://twitter.com/alexellisuk/status/845395794408693761
Via multiple build steps, you can build the application in a container. Then, from another container (that will run the application), you only receive what it’s needed to run the application.
Would you like me to write something on a multi-stage Dockerfile?
The beauty of the multi-stage build approach is that now every machine that has Docker installed can build this application directly from the source, even if it does not have, for instance, the .NET SDK installed :)
Here are some of my notes:
- When you build a container, it creates a new layer with just the differences instead of copying a whole layer to the said layer.
- When you run the container, the container runtime will pull the layer(s) the container need.
- When you update a container, you only copy the difference; it is a vast difference and less resource-consuming than working with virtual machines where you have to install an operating system on them and other applications to make it work.
- Updating a container is like performing surgery on a Lego creation. You only have to swap out the necessary pieces instead of dismantling the whole thing and rebuilding it from scratch. Just be careful not to step on any stray Lego pieces - those things hurt!
SRE Thoughts
Services are the backbone of any modern application. They are like the muscles of an application, constantly flexing and communicating. As your fleet of services grows, so does the need for effective management.
But let's face it, even the strongest muscles can get strained from time to time. So, do you have solid strategies to handle them? Is there any logging strategy in place? Are your alerts set up to notify you when something goes wrong? And most importantly, have you automated the necessary actions to quickly address any issues? Don't let your services become a bunch of loose ends - orchestrate them with finesse.
Occasionally, we may encounter a bad supporting service or perhaps multiple services on the same solution that are causing system performance to suffer. In such situations, how can we gracefully isolate and redirect the intended user flow without adversely impacting the other services?
Also, when your application is working as expected, and the company starts a campaign or something similar that would drive traffic to our services, we would need a way to measure the load and scale-out (adding more services/VMs) and load balance the traffic over all our available services. Similarly, when the traffic load goes down, we would want to schedule/automate our scale-in to cut down on our resource consumption and cost.
Service reliability should be a priority as it gives your system the trust it should build; people should be able to trust that your system is able to fulfill their request and fail gracefully with an understandable response if any error or missing data is introduced.
Modern problems need modern solutions, more on this and the microservices tooling (mentioned earlier for the monoliths) coming later
— Saif;


