Zerubbabel vs the JVM


Uzi Landsmann
Systemutvecklare
Many languages live in the JVM landscape. But how do we know which one to choose? In this article, we will look into a specific aspect of some JVM languages using quite a limited looking glass: comparing several functional operations made in each language to achieve the same goal, namely analyzing the bible for some words. Hopefully, the solutions will allow us to see some differences between the JVM languages and perhaps even introduce some of the features in those languages that you might not be familiar with.
The project
We’ve created a simple specification with some requirements and a testing template to be implemented in different languages:
https://github.com/WebstepSweden/Zerubbabel
This is an attempt to solve a problem in different languages using a functional programming paradigm, in order to compare the different implementations.
The Problem: how many times does the word God appear in the Bible? And how about Jesus? Is there more love than hate in the bible? How about sheep vs goats? And most importantly, is there really a guy named Zerubbabel in the Bible? In this project, we intend to analyze the bible text and create a dictionary with words as keys and the number of appearances as values, in order to draw some conclusions about the questions above.
The subprojects: different implementations are to be added in folders with the specific language implementation inside them.
The text: a text file called bible.txt resides in the root folder. When implementing a subproject, the file should be copied to it and used by the implementation.
The words: all the words in the text file should be read into a list or an array, and transformed into lowercase.
The filters:
- empty words are to be removed using the following regex: ^\w+
- the following boring words should be removed: the, and, of, to, that, for, in, i, his, a, with, it, be, is, not, they, thou
The dictionary: all the words in the text should be grouped using the distinct words as keys and the number of places in which they appear as values. This dictionary is the return value of a function.
The tests: in order to test the implementation, the following tests need to be created:
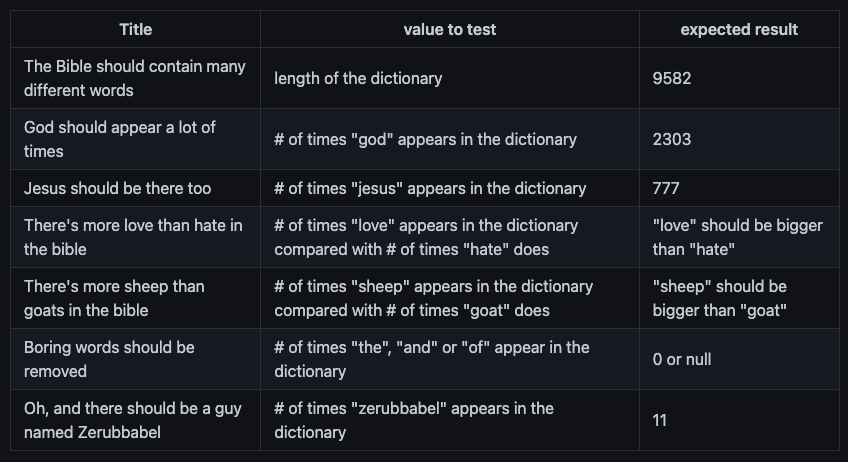
We have then attempted to implement the solution in multiple JVM languages, described below.
Implementations
In this section, we discuss what the implementations look like in the different languages, what we got stuck on, and what we liked while writing the code. We summarize with a list of pros and cons.
Java
First of all, we’ve implemented a solution using the most popular language in the JVM, Java. We’re using the nio library to comfortably fetch the text file, then use the stream library to create fluent code. We use multiple static imports to make the code even more readable (where it makes sense: statically importing List.of(), for example, would not help because of(1,2,3) does not make the code any clearer).
pros: fluent code, nio makes it easy to read strings from a file
cons: every lambda call requires a named variable.
package zer.ubba.bel;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.List;
import java.util.Map;
import java.util.regex.Pattern;
import static java.lang.ClassLoader.getSystemResource;
import static java.util.Arrays.stream;
import static java.util.function.Function.identity;
import static java.util.stream.Collectors.counting;
import static java.util.stream.Collectors.groupingBy;
public class JavaBible {
private final List<String> boringWords = List.of(("the,and,of,to,that,for,in,i,his,a,with,it,be,is,not,they,thou")
.split(","));
Map<String, Long> readTheBible() throws Exception {
final var path = Paths.get(getSystemResource("bible.txt").toURI());
return Files.lines(path)
.flatMap(line -> stream(line.split(" ")))
.filter(Pattern.compile("^\\w+").asMatchPredicate())
.map(String::toLowerCase)
.filter(word -> !boringWords.contains(word))
.collect(groupingBy(identity(), counting()));
}
}Kotlin
Next up was Kotlin. The solution is quite elegant, though the .groupingBy { it }.eachCount() part is far from obvious and like much other stuff, you need to google it/stackoverflow it to know it. We use the automatic it variable in the lambdas which makes the functions slightly more compact.
pros: compact code
cons: grouping/counting is non-trivial
package zer.ubba.bel
import java.io.File
import java.lang.ClassLoader.getSystemResource
import java.util.Locale
private val boringWords = ("the,and,of,to,that,for,in,i,his,a,with,it,be,is,not,they,thou")
.split(",")
fun readTheBible(): Map<String, Int> {
val file = File(getSystemResource("bible.txt").file)
return file
.readLines()
.flatMap { it.split(" ") }
.filter { """^\w+""".toRegex().matches(it) }
.map { it.lowercase(Locale.getDefault()) }
.filter { !boringWords.contains(it) }
.groupingBy { it }.eachCount()
}Scala
The Scala solution is quite similar to the Kotlin one, but here we use _ as the automatic variable in the lambdas. A quirk we found was that the filter() function returns an iterator, for which the groupBy() method is not defined, so we had to convert it into a list before grouping the words. The mapValues() method was quite a straightforward way to map the list of words into the size of the list.
pros: compact code, fromResource() function makes life easy
cons: need to convert to list before grouping
package zer.ubba.bel
import scala.io.Source.fromResource
class ScalaBible {
private val boringWords = ("the,and,of,to,that,for,in,i,his,a,with,it,be,is,not,they,thou")
.split(",")
def readTheBible(): Map[String, Int] = {
val source = fromResource("bible.txt")
source
.getLines
.flatMap(_ split " ")
.filter(_ matches """^\w+""")
.map(_.toLowerCase)
.filter(!boringWords.contains(_))
.toList
.groupBy(identity)
.mapValues(_.size)
}
}Groovy
In Groovy, the standard lambda names have been replaced with other, less straightforward ones, like collect() instead of map() and findAll() instead of filter() — which takes some getting used to. Also, we’re missing the flatMap() function and had to use flatten() instead, which unfortunately returns a List<?> so we had to m̶a̶p̶ collect it back to a list of strings before continuing. An extra bonus was though the countBy() method that did exactly what we needed. Why don’t other languages have this feature?
pros: the countBy() method is great
cons: non-standard lambda method names, flatMap() is missing
package zer.ubba.bel
class GroovyBible {
private final def boringWords = "the,and,of,to,that,for,in,i,his,a,with,it,be,is,not,they,thou"
.split(",");
def readTheBible() {
def resource = ClassLoader.getSystemResource("bible.txt")
return resource
.readLines()
.collect { it.split(" ") }
.flatten()
.collect { it.toString() }
.findAll { it.matches("^\\w+") }
.collect { it.toLowerCase() }
.findAll { !boringWords.contains(it) }
.countBy { it }
}
}Clojure
Clojure is…different. Also, it uses its own lambda names which takes some googling to find the correct one — so slurp mean read file and mapcat means flatMap. The most confusing part was trying to find a way to filter out the boring words. Apparently, contains is one of the most confusing functions in Clojure, and we had to reinvent the wheel a bit and fiddle with some and some? to find a solution (probably not the best one) to remove the boring words. Also, we’ve used multiple def variables to make the code more readable, but we’re guessing more competent Clojure developers would probably not need those and would write a much more compact and beautiful code.
pros: the frequencies method is great, (potentially) very compact code
cons: non-standard lambda method names, filtering boring words was non-trivial.
(ns zer.ubba.bel.clojure_bible
(:require [clojure.java.io :as io])
(:require [clojure.string :as str])
(:gen-class))
(def data-file (io/resource "bible.txt"))
(def boringWords
(str/split "the,and,of,to,that,for,in,i,his,a,with,it,be,is,not,they,thou" #","))
(defn readTheBible []
(def text (slurp data-file))
(def lines (str/split text, #"\n"))
(def words (mapcat #(str/split % #" ") lines))
(def noempty (filter #(re-matches #"^\w+" %) words))
(def lower (map #(str/lower-case %) noempty))
(defn isboring [word] (some? (some #(= word %) boringWords)))
(def noboring (remove #(isboring %) lower))
(frequencies noboring))
Tests
Though there are many test framework alternatives, we tried using the most typical one for each language, give an example of some tests and describe them below.
Java
The Java tests are written using JUnit 5. They are simple and straightforward, although the test method names are compressed and are a bit hard to read. Some people also consider the parameter order in the assertion methods confusing (which one is expected and which is the actual result?), and assertion frameworks like AssertJ and Hamcrest are used frequently instead of the JUnit ones or in addition to them.
pros: simple and easy
cons: test method names are somewhat hard to read, assertions are a bit confusing
package zer.ubba.bel;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import java.util.Map;
import static org.junit.jupiter.api.Assertions.assertEquals;
import static org.junit.jupiter.api.Assertions.assertTrue;
class JavaBibleTest {
private static Map<String, Long> bibleDictionary;
@BeforeAll
static void setUpBeforeClass() throws Exception {
bibleDictionary = new JavaBible().readTheBible();
}
@Test
void theBibleShouldContainManyDifferentWords() {
assertEquals(9582, bibleDictionary.size());
}
@Test
void godShouldAppearALotOfTimes() {
assertEquals(2302, bibleDictionary.get("god"));
}
// more tests...
}
The error message we receive when the test fails is quite clear:
org.opentest4j.AssertionFailedError:
Expected :2302
Actual :2303
<Click to see difference>at org.junit.jupiter.api.AssertionUtils.fail(AssertionUtils.java:55)
at org.junit.jupiter.api.AssertionUtils.failNotEqual(AssertionUtils.java:62)
at org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:182)
at org.junit.jupiter.api.AssertEquals.assertEquals(AssertEquals.java:177)
at org.junit.jupiter.api.Assertions.assertEquals(Assertions.java:635)
at zer.ubba.bel.JavaBibleTest.godShouldAppearALotOfTimes(JavaBibleTest.java:27)
...more stack lines...
Kotlin
We’re using Kotest to test Kotlin. The test method names are given as strings and are easy to read. The infix assertions, like shouldBe, make the tests very clear as well. The test class declaration, including the StringSpec thing, is a bit special with that combination of parentheses and curly brackets but is not too annoying.
pros: readable test method names and assertions
cons: strange class declaration
import io.kotest.core.spec.style.StringSpec
import io.kotest.matchers.comparables.shouldBeGreaterThan
import io.kotest.matchers.shouldBe
import zer.ubba.bel.readTheBible
class KotlinBibleTest : StringSpec({
val bibleDictionary = readTheBible();
"The Bible should contain many different words" {
bibleDictionary.size shouldBe 9582
}
"God should appear a lot of times" {
bibleDictionary["god"] shouldBe 2303
}
// more tests...
})
Even here, the error message we receive when the test fails is quite clear:
expected:<2302> but was:<2303>
Expected :2302
Actual :2303
<Click to see difference>io.kotest.assertions.AssertionFailedError: expected:<2302> but was:<2303>
at KotlinBibleTest$1$2.invokeSuspend(KotlinBibleTest.kt:15)
at KotlinBibleTest$1$2.invoke(KotlinBibleTest.kt)
...more stack lines...
Scala
For Scala, we’re using the ScalaTest framework, though some people prefer using Specs2. It is straightforward and easy to write tests using it and has a lot of nice matchers like should be > and shouldNot contain — although we had to choose carefully when trying to find the correct matcher to import.
pros: readable test method names and assertions, rich matcher library with infix matchers
cons: finding the correct matcher to import can be a challenge
import org.scalatest.funsuite.AnyFunSuite
import zer.ubba.bel.ScalaBible
class ScalaBibleTest extends AnyFunSuite {
private val bibleDictionary = new ScalaBible().readTheBible();
test("The Bible should contain many different words") {
bibleDictionary.size shouldBe 9582
}
test("God should appear a lot of times") {
bibleDictionary("god") shouldBe 2303
}
// more tests...
}Even Scalatest shows a clear error message when the test fails:
2303 was not equal to 2302
ScalaTestFailureLocation: ScalaBibleTest at (ScalaBibleTest.scala:16)
Expected :2302
Actual :2303
<Click to see difference>org.scalatest.exceptions.TestFailedException: 2303 was not equal to 2302
at org.scalatest.matchers.MatchersHelper$.indicateFailure(MatchersHelper.scala:392)
at org.scalatest.matchers.should.Matchers$AnyShouldWrapper.shouldBe(Matchers.scala:7021)
Groovy
Spock is probably the most popular testing framework for Groovy. The tests are written in a BDD manner using different blocks like given, when and then or, as in our case, simply expect. This gives the tests a nice structure and separates the different parts. We were a bit confused when it came to the dictionary instance that is used by all the tests, and it took some googling to realize that we need to use the @Shared annotation for it.
pros: well structured BDD-like tests using test blocks
cons: shared variables are a bit confusing at first
package zer.ubba.bel
import spock.lang.Shared
import spock.lang.Specification
class GroovyBibleTest extends Specification {
@Shared
def bibleDictionary = new GroovyBible().readTheBible()
def "The Bible should contain many different words"() {
expect:
bibleDictionary.size() == 9582
}
def "God should appear a lot of times"() {
expect:
bibleDictionary["god"] == 2303
}
// more tests...
}
We find the error message incredibly clear and useful, pointing us to the exact location where the error occurs:
Condition not satisfied:
bibleDictionary[“god”] == 2302
| | |
| 2303 false
[old:264, testament:8, king:1793,....]Clojure
clojure.test is the default test framework used for testing Clojure, using the is macro for assertions. We import it and our clojure_bible file using :require and can then write our tests in a quite readable, clojure manner.
pros: clear test names, the is macro is quite straightforward to use
cons: no matchers are used. Instead, we’re using operators like =, <, > etc.
(ns zer.ubba.bel.clojure_bible_test
(:require [clojure.test :refer :all]
[zer.ubba.bel.clojure_bible :refer :all]))
(deftest bible-test
(def bibleDictionary (readTheBible))
(testing "The Bible should contain many different words"
(is (= (.size bibleDictionary) 9582)))
(testing "God should appear a lot of times"
(is (= (get bibleDictionary "god") 2303)))
; more tests...
The error message we receive is rather clear as well:
FAIL in (bible-test) (clojure_bible_test.clj:13)
God should appear a lot of times
expected: (= (get bibleDictionary “god”) 2302)
actual: (not (= 2303 2302))
Final words
We know that there are more JVM languages but chose to compare only the high-profile languages. This comparison was not in any way done in an academic way and is highly subjective. Also, as described above, we only wanted to highlight a small aspect of the languages — a few functional operations — but we hope we managed to show how a similar goal can be achieved in each of the different languages and to provide a glimpse into those and to the way we use different test frameworks to test them.
Finally, the project is open to adding more programming languages than the ones living in the JVM. If you wish to add an implementation in your favorite language, you’re more than welcome to add a pull request in the Zerubbabel project.


