Language Processing (NLP) for beginners


Kasra Mohaghegh
Data Scientist
According to Wikipedia “Natural Languages Processing (NLP) is a subfield of computer science and artificial intelligence concerned with interactions between computers and human (natural) languages. It is used to apply machine learning algorithms to text and speech.”
I am an experienced Numerical Analyst with a PhD Degree focused in Numerical analysis and Computational Linear Algebra. I have been working as a data scientist during past years and my focus was NLP and managing data pipelines.
NLP has been used in many different applications such as: speech recognition, document summarization, machine translation, spam detection, named entity recognition, question answering, autocomplete, predictive typing
When we are speaking about NLP for machines, we mean:
- Analyse, understand and generate human languages just like humans do
- Applying computational techniques to language domain
- To explain linguistic theories to build systems that can be of social use
- Started off as a branch of Artificial Intelligence
- Borrows from Linguistics, Psycholinguistics, Cognitive Science & Statistics
- Make computers learn our language rather than we learn theirs
In the following we start with a brief history of NLP from beginning of 20th century till quite recently then continue with some challenges and see why NLP is so hard. In the next we will discuss the components of NLP and make a brief discussion on how model and data training might be done.
I used spaCy an open-source library for NLP in Python. Most of the examples discussed in the following took from spaCy document.
What is spaCy?
- spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python.
- spaCy is designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems, or to pre-process text for deep learning.
What is spaCy NOT?
- spaCy is not a platform or “an API”. Unlike a platform, spaCy does not provide a software as a service, or a web application. It’s an open-source library designed to help you build NLP applications, not a consumable service.
- spaCy is not an out-of-the-box chat bot engine. While spaCy can be used to power conversational applications, it’s not designed specifically for chat bots, and only provides the underlying text processing capabilities.
- spaCy is not research software. It’s built on the latest research, but it’s designed to get things done.
- spaCy is not a company. It’s an open-source library. Our company publishing spaCy and other software is called Explosion AI.
Brief history of NLP
- A Swiss linguistics Prof. Ferdinand de Saussure in early 1900s introduce. The concept of “Language as a Science.” Upon his death two of his students, Albert Sechehaye and Charles Bally, published his lecture notes in a book called: “Cours de linguistique générale”.
- In 1950, Alan Turing wrote a paper describing a test for a “thinking” machine. Machine could be part of a conversation using a teleprint
- in 1952, The Hodgkin-Huxley model brain uses neurons in forming an electrical network
- In 1957 Noam Chomsky’s book, Syntactic Structures. It was predicted that “machine translation” can be solved in 3 years. Mostly hand-coded rules or linguistics-oriented approaches. The 3-year project continued for 10 years.
- Mid 1960’s — Mid 1970’s: A Dark Era. After the initial hype, a dark era follows — people started believing that machine translation is impossible, and most abandoned research for NLP.
- 1970’s and early 1980’s — Slow Revival of NLP. Some research activities revived, but the emphasis is still on linguistically oriented, working on small toy problems with weak empirical evaluation
- Late 1980’s and 1990’s — Statistical Revolution! By this time, the computing power increased substantially. Data-driven, statistical approaches with simple representation win over complex hand-coded linguistic rules.
“Whenever I fire a linguist our machine translation performance improves.” (Jelinek, 1988)
- 2000’s — Statistics Powered by Linguistic Insights. With more sophistication with the statistical models, richer linguistic representation starts finding a new value.
Why NLP
- A hallmark of human intelligence
- Text is the largest repository of human knowledge and is growing quickly, it is highly unstructured.
- computer programmes that understood text or speech
- NLP is used to acquire insights from massive amount of textual data − E.g., hypotheses from medical, health reports
- NLP has many applications
- NLP is hard!

It is all about ambiguities. i.e. one sentence can have many meanings.
The simple sentence “I made her duck.” could have five different meanings.
- I cooked waterfowl for her.
- I cooked waterfowl belonging to her.
- I created the (toy or sculpture?) duck she owns.
- I caused her to quickly lower her head or body.
- I turned her into waterfowl (using my magic wand?).
First, the words duck and her are morphologically or syntactically ambiguous in their part-of-speech.
- Duck can be a verb or a noun, while
- her can be a dative pronoun or a possessive pronoun.
Second, the word make is semantically ambiguous; it can mean create or cook.
Finally, the verb make is syntactically ambiguous in a different way.
- Make can be transitive, that is, taking a single direct object (2), or
- it can be ditransitive, that is, taking two objects (5), meaning that the first object (her) got made into the second object (duck)
- Finally, make can take a direct object and a verb (4), meaning that the object (her) got caused to perform the verbal action (duck).
What are the techniques used in NLP?
- Syntactic analysis: Syntactic analysis is defined as analysis that tells us the logical meaning of certain given sentences or parts of those sentences.
- Semantic analysis: The purpose of semantic analysis is to draw exact meaning, or you can say dictionary meaning from the text. The work of semantic analyser is to check the text for meaningfulness.
Syntax refers to the arrangement of words in a sentence such that they make grammatical sense.
- Morphological segmentation/Tokenization. It involves dividing words into individual units
- Lemmatization/Stemming. It involves cutting the inflected words to their root form.
- Part-of-speech tagging. It involves identifying the part of speech for every word.
- Parsing. It involves undertaking grammatical analysis for the provided sentence.
Tokenization

- Tokenization is essentially splitting a phrase, sentence, paragraph, or an entire text document into smaller units, such as individual words or terms. Each of these smaller units are called tokens.
Why is Tokenization required in NLP?
- meaning of the text could easily be interpreted by analysing the words present in the text.
- count the number of words in the text
- count the frequency of the word, that is, the number of times a particular word is present, omit stopwords
In some languages, there is no space between words, or a word may contain smaller syllables
- 私の名前はカスラです。スウェーデンの企業Webstepのデータサイエンティストです。
- German Word ”Lebensversicherungsgesellschaftangestellter”, English translation “Life Insurance Company employee”
Lemmatization
- Lemmatization is the process of reducing a word to its base form, its mother word in some sense.
- Why it is useful?
Immediate use case is in text classification. It is avoided word duplication and so build a clearer picture of patterns of word usage in multiple documents.
Pos Tagging
Part-of-speech tagging is the process of assigning grammatical properties (e.g. noun, verb, …) to words.
- Words with same POS taging tend to follow a similar syntactic structure, like “ ‘s ”
- Process of determining the syntactic structure of a text by analysing its constituent words based on an underlying grammar (of the language).
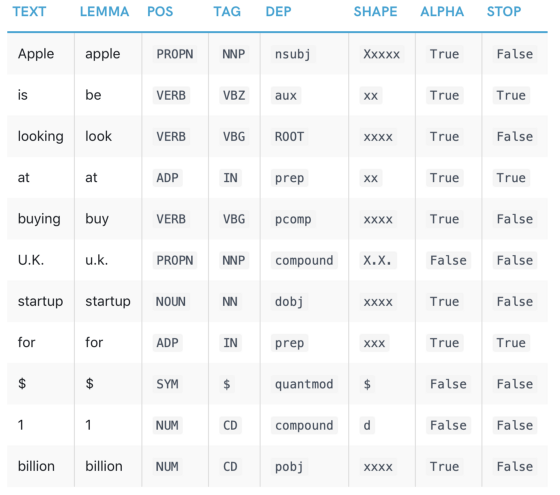
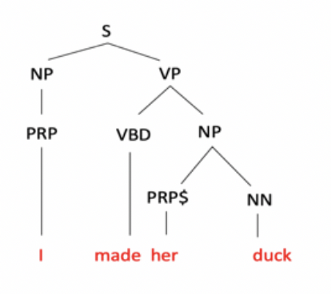
Ambiguty: “I made her duck” solving with NLP.
POS tagging: “duck” can be a N or V:
- V: I caused her to quickly lower her head or body
- N: I cooked waterfowl for her benefit (to eat).
POS tagging: “her” can be a possessive (“of her”) or dative (“for her”) or accusative pronoun:
- Possessive: I cooked waterfowl belonging to her.
- Dative: I cooked waterfowl for her benefit (to eat).
- Accusative: I waved my magic wand and turned her into waterfowl.
WSD: “make” can mean “create” or “cook”:
- Create: I made the (plaster) duck statue she owns
- Cook: I cooked waterfowl belonging to her.
Syntactic Parsing
Simply speaking, parsing in NLP is the process of determining the syntactic structure of a text by analyzing its constituent words based on an underlying grammar (of the language).

Make can be Ditransitive (verb has 2 noun objects): I made [her] (into) [undifferentiated waterfowl.]
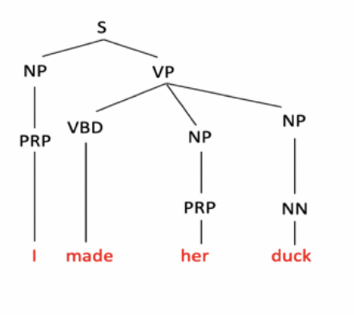
Make can be Action-transitive: I caused [her][to move her body]
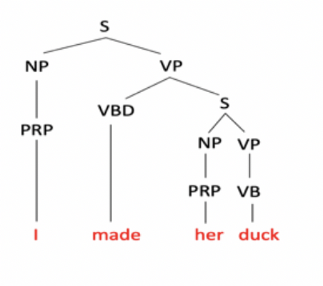
Make can be Transitive (verb has a noun direct object): I cooked waterfowl belonging to her.
Semantic Analysis
Describes the process of understanding natural language, the way that humans communicate, based on meaning and context. The purpose of semantic analysis is to draw exact meaning, or you can say dictionary meaning from the text. The work of semantic analyzer is to check the text for meaningfulness.
- Name Entity Recognition (NER)
- Sentiment Analysis
- Word2vec and similarities
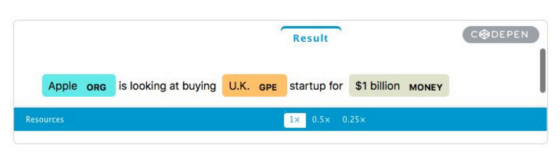
Name Entity Recognition (NER)
Name Entity Recognition (NER): process of classifying named entities found in a text into predefined categories, such as PERSON, PLACE, DATES and etc.
- An example is to distinguish between Apple the company, and apple the fruit
Sentiment Analysis
Utilizing the techniques from NLP, sentiment analysis field looks at users’ expressions and in turn associate emotions with what the user has provided.
Sentiment Analysis studies the subjective information in an expression, that is, the opinions, appraisals, emotions, or attitudes towards a topic, person or entity. Expressions can be classified as positive, negative, or neutral.
- For example: “I really like the new design of your website!” → Positive.

Word2vec
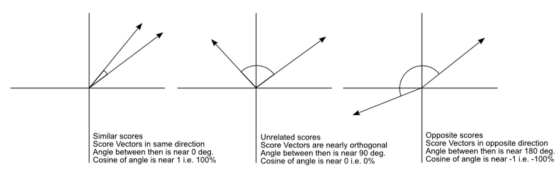
Word2vec is a two-layer neural net that processes text by “vectorizing” words. Its input is a text corpus and its output is a set of vectors: feature vectors that represent words in that corpus. While Word2vec is not a deep neural network, it turns text into a numerical form that deep neural networks can understand.
Similarity is determined by comparing word vectors. Each word has a vector of 300–500 numbers.
“dog cat banana afskfsd”
- ” token.text, token.has_vector, token.vector_norm, token.is_oov”
- dog True 7.0336733 False
- cat True 6.6808186 False
- banana True 6.700014 False
- afskfsd False 0.0 True
Comparing Similarity “dog cat banana”
- dog dog 1.0
- dog cat 0.80168545
- dog banana 0.24327643
- cat dog 0.80168545
- cat cat 1.0
- cat banana 0.28154364
- banana dog 0.24327643
- banana cat 0.28154364
- banana banana 1.0
Cosine similarity
How to train NER
- Training is not just to memorise our examples, should be generalize it to other.
- NER models are statistical and every decision is a prediction.
- A model trained on romantic novels will likely perform badly on legal texts.
- Everything is almost related to the training data.
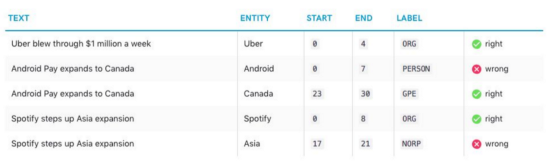
I use spaCy for training all my models. spaCy’s models are statistical and every “decision” they make — for example, whether a word is a named entity — is a prediction. This prediction is based on the examples the model has seen during training. To train a model, you first need training data, examples of text, and the labels you want the model to predict.
The training could be done via matcher and CSV list combined with Post-tagging which in some scene automatic version for preparation of annotations for training.
- Gold annotation!
- Note that a “gold-standard” isn’t always completely correct: it could have known missing information, or you could believe that some of the annotations might be incorrect.
- Fast and easy
- Tagger accuracy is important, and the model is almost deterministic behavior!
- Not easy to combine or add classes (Catastrophic interference)
Another way for training is manual annotation. I used Prodigy for manual annotations. Prodigy is a modern annotation tool for creating training and evaluation data for machine learning models. You can also use Prodigy to help you inspect and clean your data, do error analysis and develop rule-based systems to use in combination with your statistical models.
- Training via manual annotation
- Time consuming, need around 50 000 annotations for each entity class
- Gold or Silver annotation!
- Much easier to combine and built specific models
- Still has the risk of Catastrophic interference
- Statistical with higher accuracy
How to train sentiment
Sentiment analysis is quite a broad domain and there exist many tasks there. A single program cannot solve all of them. A better specification of the problem would help. For some of the problems, computer applications (commercial, open-source, desktop, web based, …) are available. Having input (training) data might be required or beneficial for some of them. You might also write your own applications in many programming languages. There are often libraries related to sentiment analysis available for the languages as well so it sometimes doesn’t have to be a complicated task.
Training via automation process/rule based
- Much faster compare to manual annotation
- Find training data is hard, I use trip adviser and twitter.
- Automation via stars or even emoji!
- Positive and negative sets
- Very unbalanced classes.
- This sentence even for Human is difficult to understand at the first glance: “This is the best laptop bag ever. It is so good that within two months of use, it is worthy of being used as a grocery bag.”
Training via manual annotation
- Time consuming
- Even for human is difficult!
- Much higher accuracy.
- I use Prodigy for manual annotation.
Sentiment of emojis by: Peter Kralj Novak
There is a new generation of emoticons, called emojis, that is increasingly being used in mobile communications and social media. They provided the emoji sentiment lexicon, called the Emoji Sentiment Ranking, and draw a sentiment map of the 751 most frequently used emojis, look at Sentiment of emojis.
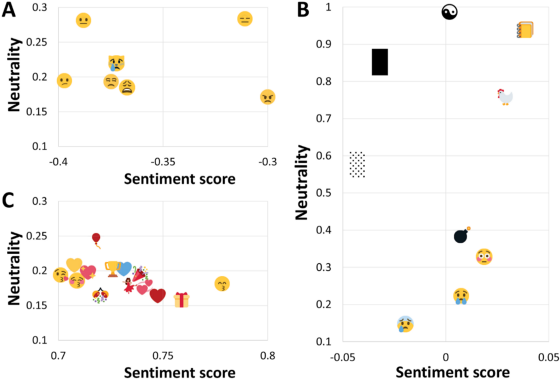
A: negative emojis, panel B: neutral (top) and bipolar (bottom) emojis, panel C: positive emojis.
- I trained a model on Twitter for Finnish language and it was over 60% accurate on 3-mood sentiment.
- On day workshop for annotating 10–15% of training data manually
- We reach slightly better accuracy on the same TEST DATA
To summarize, NLP is a powerful tool that will help one accomplish many positive objectives in many dimensions of life using easy to follow instructions. Technologies based on NLP are becoming increasingly widespread. In this post I tried to reply:
- What is NLP?
- Why it is so hard!
- What are NLP components?
- Briefly, how we could train NER and Sentiment analysis.
I hope you find this post useful and interesting!


