How to succeed with large live events

En text

Magnus Andersson
Systemutvecklare
The goal of my talk at Websteps Kompetensbio 2019 was to make the audience understand the importance of preparation in order to manage large live events.
I did this by telling the story of two real life examples, one failure and one success.
The failure example was about when Donationsregistret’s website went down because of the TV show Svenska Nyheter, who in the end of their show, which aired at 10 PM on a Friday, urged its one million viewers to go to https://www.socialstyrelsen.se/donationsregistret and register as donors.
Svenska nyheter urged its one million viewers to got the Donationsregistret’s website at the end of their show.
The appeal led to 18 500 successful registrations over the weekend, which is almost 100 times the normal traffic (they usually get 300–1000 registrations per week), but it also made their site go down and be unavailable for many of the viewers who wanted to register. I know this because I was one of those one million viewers and I couldn’t even load the start page.
In reality they had a nationwide live event on their hands and they didn’t even know about it! Or did they?
Turns out they did know about the show and they had probably made preparations but apparently they underestimated the impact of live television and public service and the cost of doing so in this case, was losing a lot of potential donors.
The success story was about what my team at Invidi do, serving ads for the world’s largest web streamed live event.
The highest peak so far was in 2019 in the final game of the match series when there were concurrent viewers in the order of tens of millions. And when all of them, at roughly the same time, needed ads to watch, there were some huge traffic hitting Invidi.
In order for you to better understand the traffic patterns we are dealing with I will now quickly explain the process of ad serving.
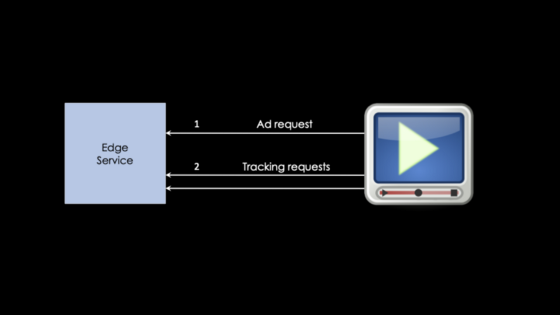
When it’s time for a user to watch ads the video player, typically in real time, sends an ad request (1) to our so called “edge service”. That is the service we have deployed in the region closest to the users in order to reduce latency.
The edge service continuously talks to other backend services and data stores in order to be prepared to tailor the perfect ad break for each user. When a user then starts to watch the ads we sent them, the video player starts to sends several tracking events (2), for reporting purposes, back to our edge service. This is events like “break started”, “started watching ad”, “watched entire ad” etc.
So the edge service usually gets a lot more tracking requests than ad requests, which is important to remember.
Here you can see the traffic, from the previously mentioned event, for ad requests and tracking that happens when the viewer joins the stream, so called pre-rolls.
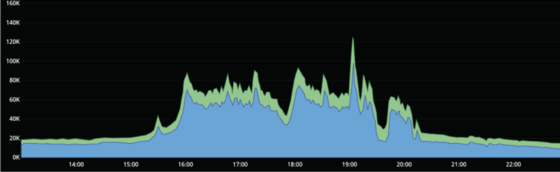
Pre-roll traffic for the final game (RPS).
To handle the big traffic spikes we scale out our “edge service” horizontally before the game starts and scale down afterwards. We can do this since we know when the games starts and ends an also have an estimated viewers count (typically depending on the playing teams popularity).
We need to do this since auto scaling doesn’t react fast enough, and that is because in order to act an (horizontal) auto scaler needs to:
- First detect that scaling is needed, which is usually done by configuring limits for metrics like CPU, memory or network usage.
- Then it typically needs to spin up new containers on new instances and when they are up and ready, which usually takes anywhere from 10 to 60 seconds, then they can start to serve ads.
So if we rely only on auto scaling and have a quick increase in ad requests as can be seen in the graph above when the game starts at 16:00, we are gonna fail to respond to most of those requests, because we can’t scale fast enough.
As said we pre scale our edge service horizontally, and we do it so that each instance won’t have to handle more than 400 RPS, which translates to, depending on estimated viewers, scaling out to anywhere from 50 to 400 instances. Scaling our infrastructure this way works well for handling the pre-roll traffic.
However, the so called mid-rolls, which is the ad breaks inserted during the game, is another story. Since everybody who have joined the stream so far watches them at roughly the same time the traffic volume and peaks are much higher and spikier than for pre-rolls.
This becomes very obvious when graphing the mid-roll tracking traffic on top of the now dwarfed pre-rolls as can be seen below. Here we can see that at around 17:35 we have a record spike of almost 1 million RPS!
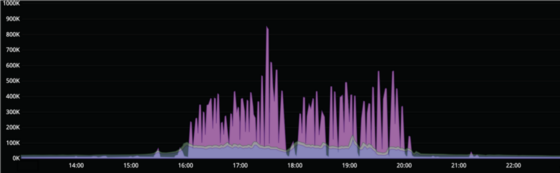
Mid-roll tracking traffic for the final game (RPS).
To handle this we actually use a CDN (Content Delivery Network), as an edge to protect us from the onslaught of requests. The CDN is configured to send the request urls to a Go app we have deployed in Google App Engine (which is Google’s managed serverless application platform).
The Go app is also pre scaled horizontally anywhere from 100 to 1200 instances, and it’s task is very simple, it just publishes the query string of the request to a Google Pub-Sub topic, from which we then can process the requests at our own rate.
On top of all this we actually do use auto scaling since it can help us to limit our losses, if we have done the same mistake as Donationsregistret, and underestimated the popularity of the live event.
Conclusion
Big live events are hard to prepare for, in particular if you only get one shot.
But if you follow these rules you have a good chance of success.
- Always monitor your services closely in order to be able to determine the optimal resource/cost balance and make good traffic estimates.
- Use auto scaling to handle slower variations and moderate peeks in traffic.
- For live events that might explode the load on your services you should always pre scale to be able to handle sudden spikes without losing traffic.
Want to read more?
If you are interested in more reading, primarily failures, you can find a lot of examples online. Simply search for “website down” (or “sajt kraschade”) and you will find many instructive and amusing reads.
Some examples from a quick search:
”Det är inte alls bra. Det kom en hejdundrande massa trafik samtidigt, vi jobbar verkligen för att få upp den”
Prisjakt.se about Black Friday 2017.
“Felsökning pågår, vi vet fortfarande inte vad som orsakade problemen”
Valmyndigheten on Swedish election day 2018.
“Väldigt många vill handla samtidigt och det är extra tryck i år”
Elgiganten about Black Friday 2019.


